Source: Quanta, May 2023
In 1928, the German mathematicians David Hilbert and Wilhelm Ackermann proposed a question called the Entscheidungsproblem (“decision problem”). In time, their question would lead to a formal definition of computability, one that allowed mathematicians to answer a host of new problems and laid the foundation for theoretical computer science.
The definition came from a 23-year-old grad student named Alan Turing, who in 1936 wrote a seminal paper that not only formalized the concept of computation, but also proved a fundamental question in mathematics and created the intellectual foundation for the invention of the electronic computer.

Turing’s great insight was to provide a concrete answer to the computation question in the form of an abstract machine, later named the Turing machine by his doctoral adviser, Alonzo Church. It’s abstract because it doesn’t (and can’t) physically exist as a tangible device. Instead, it’s a conceptual model of computation: If the machine can calculate a function, then the function is computable.
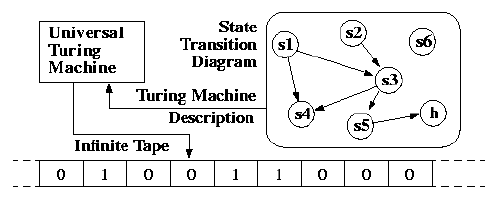
https://web.mit.edu/manoli/turing/www/turing.html
With his abstract machine, Turing established a model of computation to answer the Entscheidungsproblem, which formally asks: Given a set of mathematical axioms, is there a mechanical process — a set of instructions, which today we’d call an algorithm — that can always determine whether a given statement is true?
in 1936, Church and Turing — using different methods — independently proved that there is no general way of solving every instance of the Entscheidungsproblem. For example, some games, such as John Conway’s Game of Life, are undecidable: No algorithm can determine whether a certain pattern will appear from an initial pattern.
“I think it is commonly accepted that the Church-Turing thesis says that the informal notion of algorithm corresponds to what any ‘reasonable’ computational model can do.” Other mathematicians have come up with different models of computation that look quite different on the surface but are actually equivalent: They can do any computation that Turing machines can do, and vice versa.
Only a few years after Kurt Gödel had proved that mathematics was incomplete, Church and Turing showed with this work that some problems in mathematics are undecidable — no algorithm, however sophisticated, can tell us whether the answer is yes or no. Both were devastating blows to Hilbert, who had hoped mathematics would have tidy, idealized answers. But it’s perhaps just as well: If a general solution to the Entscheidungsproblem existed, it would mean that all problems in mathematics could be reduced to simple mechanical calculations.
Sanjeev Arora, a theoretical computer scientist at Princeton University … emphasizes a broader philosophical picture.
“There’s two notions of ‘universal,’” he said. “One notion of the universal is that it can run any other Turing machine. But the other, bigger notion of ‘universal’ is that it can run any computation that you will come up with in the universe.” In the world of classical physics, any physical process can be modeled or simulated using algorithms, which, in turn, can be simulated by a Turing machine.”